
Dopo tanti anni di affinamento delle tecniche di misura dei sistemi di altoparlanti c’era ancora un punto fondamentale che per tutti noi dello staff tecnico era motivo di profonda insoddisfazione, una lacuna descrivibile con considerazioni semplici, persino “primitive”. La prima è che la musica è fatta di segnali in divenire tumultuoso e rapidissimo, mentre gran parte di quelli impiegati nelle prove sono di tipo statico, invarianti nel tempo. La seconda è che le misure di distorsione, sicuramente tra le più significative, vengono di norma fatte a potenze molto basse proprio a causa della natura continua dei segnali impiegati fino ad oggi, mentre in sala d’ascolto un amplificatore da 100 watt può “scaricare” quasi tutta la sua potenza anche sul solo tweeter, sia pure per tempi molto brevi. Ma da oggi si cambia.
 Questo articolo è una sintesi di quello, più esteso, pubblicato sul numero di novembre della “grande madre” del nostro gruppo, AUDIOreview, ed intende descrivere motivazioni e modalità esecutive delle nuove misure audio sui sistemi di altoparlanti che anche su Digital Video impieghiamo già dallo scorso mese.
Questo articolo è una sintesi di quello, più esteso, pubblicato sul numero di novembre della “grande madre” del nostro gruppo, AUDIOreview, ed intende descrivere motivazioni e modalità esecutive delle nuove misure audio sui sistemi di altoparlanti che anche su Digital Video impieghiamo già dallo scorso mese.
I primordi: la lunga era dei segnali stazionari
Quando l’alta fedeltà mosse i primi passi, intorno agli anni ’40, esistevano già ottimi generatori di segnali, validi microfoni e buoni amplificatori di segnale, ma gli analizzatori erano inesorabilmente basati su filtri analogici e potevano quindi funzionare, non senza consistenti limiti, solo con segnali di tipo continuo. Per misurare le prestazioni d’un altoparlante c’era una sola via: generare segnali il più possibile “puliti”, applicarli all’altoparlante, prelevarli con il microfono, passarli all’analizzatore e poi impiegare del tempo per azzerare la frequenza fondamentale e quantificare il residuo. Essendo il segnale di prova invariante nel tempo, al microfono giungevano insieme sia il segnale diretto che quello riflesso dall’ambiente, e quest’ultimo, a frequenze sufficientemente basse (da parecchie centinaia di Hz in giù), in un ambiente non opportunamente trattato può anche sovrastare il livello del segnale diretto, e comunque interferisce con esso: per questo motivo nacquero le celeberrime camere anecoiche, ovvero quei particolari ambienti chiusi in cui ogni parete è rivestita di materiale fonoassorbente di forma e dimensioni tali (di norma sono cunei di materiale poroso) da assicurare la quasi totale attenuazione dei suoni incidenti emessi internamente o provenienti dall’esterno. La camera anecoica è un ambiente molto particolare, in cui vale senz’altro la pena di entrare almeno una volta per saggiare di persona la correttezza delle teorie sull’equilibrio statico degli esseri umani (che dipende anche dalle informazioni che al sistema nervoso giungono dall’orecchio), ma ha il difetto di costare molto, essere molto ingombrante e di porre comunque dei limiti, perché per poter attenuare bene anche le prime due ottave della banda delle frequenze udibili deve assumere dimensioni davvero enormi. Negli anni ’40/’50/’60 non esisteva comunque alternativa: chi voleva fare misure di distorsione sugli altoparlanti doveva disporre per forza di una camera anecoica, ed in ogni caso i tecnici dovevano usare segnali stazionari e quindi di potenza molto moderata, perché i midrange ed ancor più i tweeter possiedono una massa termica modesta ed una resistenza termica bobina/ambiente molto elevata, tali da produrre bruciature nel gruppo mobile dopo pochi secondi dall’applicazione di potenze consistenti.
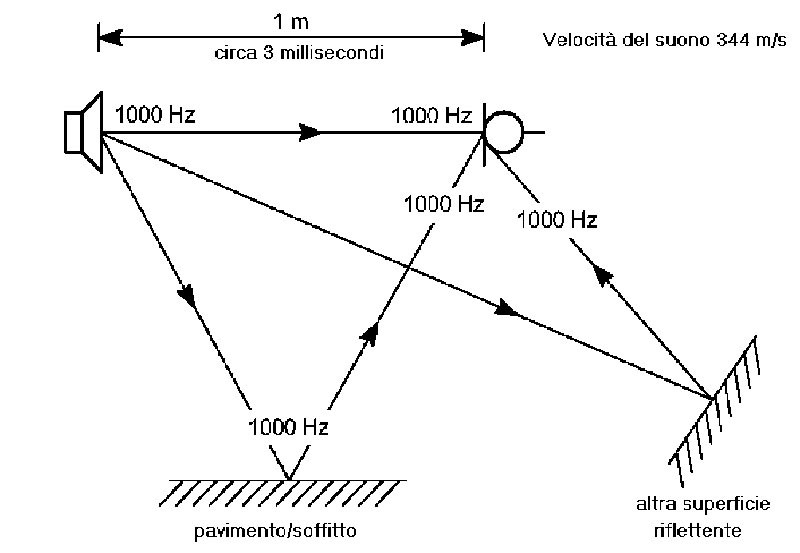
Figura 1. Se il set di strumenti disponibili per effettuare misure acustiche su sistemi di altoparlanti impone l’uso di segnali stazionari, è assolutamente necessario operare in condizioni anecoiche (assenza di suoni riflessi), altrimenti, come nell’esempio riportato, le immagini riflesse cambiano nettamente l’intensità percepita (generando un andamento ondulatorio dall’aspetto di un “pettine”).
Poi, negli anni ’60, alcuni matematici statunitensi scoprirono la Fast Fourier Transform, un potente algoritmo di calcolo che permetteva di ottenere in tempi ragionevolmente brevi un’ottima approssimazione dello spettro di un segnale digitalizzato da un convertitore analogico/digitale. Nasceva quindi la possibilità di effettuare misure sia di risposta che di distorsione in regime dinamico, possibilità che divenne concreta nei primi anni ’70, con l’introduzione sul mercato dei primi analizzatori FFT integrati. Con la comparsa di strumenti di questo tipo anche i segnali di prova cambiarono e nei laboratori audio, al posto delle proverbiali lente “spazzolate” sinusoidali (quelle, per intenderci, usate in molti film di fantascienza degli anni ’50 e ’60), si iniziò ad ascoltare suoni ancora più strani, come le “sweeppate” rapide (swept sine), i burst di rumore ed i click degli impulsi, ed in ultimo anche le sequenze di massima lunghezza (MLS). Con segnali di questo tipo si possono ottenere misure acustiche corrette analizzando la sola porzione anecoica di segnale, ovvero limitando il tempo di acquisizione agli istanti in cui al microfono giungono solo i segnali emessi dall’altoparlante (se questo è collocato ad una sufficiente distanza dagli elementi ambientali riflettenti). In un ambiente di dimensioni “normali”, con distanza minima delle pareti pari ad esempio a tre metri, collocando il diffusore al centro e piazzando il microfono ad un metro si può disporre di una finestra anecoica massima pari a circa 6.3 ms, corrispondenti ad un ciclo di segnale a 160 Hz: questa è la “frequenza di taglio inferiore” della geometria di rilevazione, a meno di non usare sistemi dedicati particolari in grado di “sopprimere” virtualmente le riflessioni (ad esempio il Brüel & Kjær 2012 che il nostro staff impiega con soddisfazione ormai da un decennio). Purtroppo anche questi sistemi impiegano un segnale semi-stazionario per misurare le distorsioni, il che non consente di effettuare test a potenza elevata. Quello della frequenza limite inferiore non è peraltro un problema insuperabile, perché alle basse frequenze è possibile ricorrere senza grandi controindicazioni alla tecnica cosiddetta del “campo vicino”, che consiste nel mettere il microfono a brevissima distanza da altoparlanti e/o condotti, con il risultato di un enorme aumento del rapporto tra pressione emessa e pressione riflessa nel segnale captato. Dalle frequenze medio-basse in su questa possibilità scema ed il microfono deve necessariamente essere collocato ad una certa distanza dall’altoparlante (di norma 1 metro).

Figura 2. Se invece il segnale è variabile nel tempo è possibile “sintonizzare” entro limiti definiti il sistema di acquisizione con il solo segnale diretto. Questo principio è alla base del funzionamento di sistemi quali il celebre Techron TEF (il primo ad implementare la Time Delay Spectrometry ideata da Dick Hayser alla fine degli anni ’60) e del Brüel & Kjær 2012. Purtroppo anche in questi casi la durata minima richiesta per il segnale non è compatibile con i limiti termici dei sistemi di altoparlanti, ed anche laddove lo fosse le bobine si scalderebbero eccessivamente, alterando i parametri di base.
Fino ad oggi, Digital Video ed AUDIOreview hanno utilizzato segnali di tipo non stazionario, o misto, per le misure di risposta in frequenza, risposta nel tempo, MIL e MOL. Tutte le altre sono state condotte con segnali variabili molto lentamente, assimilabili in pratica a segnali statici, e quindi a potenze moderate se non irrilevanti. Se nel caso dell’impedenza (che viene misurata a pochi milliwatt) ciò non comporta grandi perdite in termini di significatività del test, nel caso delle distorsioni ciò ha limitato a 90 dB il livello medio di pressione di prova, vale a dire una potenza efficace applicata pari, ad esempio, ad appena due watt per un sistema di altoparlanti con sensibilità di 87 dB. È perfino banale osservare che nell’uso concreto le normali potenze in gioco possono essere molto, molto più elevate, ed è altrettanto scontato attendersi che proprio ai livelli più alti possano emergere le più grandi differenze comportamentali tra i sistemi di altoparlanti in prova, come già avviene oggi con i test di MIL e MOL. Le misure di pressione massima indagano però il comportamento limite dei sistemi, inteso come valori di potenza e pressione oltre i quali le non linearità diventano non più accettabili. Lo scopo dei test di distorsione, seppur di norma correlato con i valori ottenuti nei test di MIL e MOL, muove ovviamente da un intento diverso: conoscere, a parità di pressione o di potenza, qual è la distorsione introdotta da ciascun sistema di altoparlanti. Ed è evidentemente quest’ultimo il dato più interessante in relazione al normale uso di questi prodotti.

Figura 3. Utilizzando dei treni d’onde (burst) si hanno due svantaggi: il tempo di misura sale notevolmente (ma ciò è d’altro canto inevitabile se si desidera impedire il raggiungimento di alte temperature alle alte potenze di prova) ed il possibile effetto di offset iniziale, che può produrre un eccesso di escursione. Per evitare tutto questo basta analizzare burst costituiti da un numero minimo di cicli. La necessaria pesatura trigonometrica (qui, in nero, è riportata la forma di quella di Blackman) della finestra di segnale acquisita elimina poi pressoché del tutto gli effetti di “leakage” conseguenti.
Misure di distorsione armonica in regime dinamico
Per misurare la risposta in frequenza con segnali non stazionari non sussistono particolari vincoli sulla natura del segnale di prova: basta che questo sia energeticamente “abbastanza” uniforme nella banda di analisi per potere, attraverso il rapporto tra la trasformata del segnale di uscita e quella del segnale di ingresso, ricostruire modulo e fase della risposta.
Per la distorsione, premesso l’intento di voler fare misure nella regione delle potenze elevate e quindi con segnali eccitanti brevi, il discorso è completamente diverso perché al momento attuale non esiste una metodica in grado di generare analisi d’insieme. Per ottenere risultati facilmente comprensibili e (non meno importante) confrontabili con quelli pubblicati fino ad oggi è necessario far muovere gli altoparlanti con andamento sinusoidale, ovvero fare misure frequenza per frequenza. Con questi presupposti il segnale di prova non ha alternative: treni d’onde (burst) sinusoidali, captati in campo vicino a bassa frequenza e ponendo il microfono a distanze sufficienti dalle medio-basse in su (in questo caso sincronizzando l’acquisizione in modo da prelevare la sola finestra anecoica). Il calcolo della distorsione viene poi realizzato banalmente mediante FFT, esattamente come già avviene per MIL e MOL. Dai riscontri effettuati i risultati appaiono ampiamente correlabili con quelli che si otterrebbero usando sinusoidi stazionarie, ma riguardo questo punto occorre anche puntualizzare alcune distinzioni importanti.
Treni di sinusoidi e sinusoidi, equivalenza parziale
La tecnica di misura che abbiamo descritto altro non è che un metodo per “ingannare” la strumentazione, alla quale viene chiesto di analizzare un segnale come se questo fosse periodico, mentre in effetti vale zero sia prima che dopo la finestra trasformata. Tale circostanza ha due conseguenze importanti:
- L’energia consegnata al sistema in prova non è spettralmente concentrata su una sola frequenza, ovviamente quella della sinusoide usata per generare il burst, bensì è “sparpagliata” su uno spettro molto largo, seppur con una concentrazione maggiore proprio nel punto suddetto. In altre parole, se inviamo una sinusoide pura da 1 kHz ad un sistema a tre vie udiremo il suono uscire in pratica solo dal midrange, mentre se gli inviamo un burst costituito da una decina di cicli quel che esce dal mid sarà ancora prevalente, ma anche woofer e tweeter entreranno marginalmente in gioco.
- L’emissione del sistema di altoparlanti non va subito a regime, bensì presenta sovente un offset di attacco in cui la pressione istantanea può anche crescere o diminuire considerevolmente rispetto ai valori stazionari. Questa è una conseguenza diretta della larga distribuzione spettrale del segnale impiegato e si manifesta quando la funzione di trasferimento del componente in prova presenta delle non linearità in tale banda: in pratica sempre, sebbene con escursioni di norma moderate.
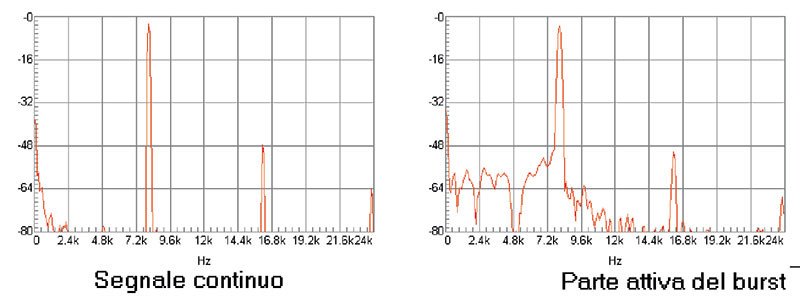
Figura 4. La misura della distorsione mediante burst sinusoidali equivale ad un “inganno” nei confronti della strumentazione, cui viene “fatto credere” di avere a che fare con un segnale ciclico di periodo pari alla finestra acquisita, mentre invece questi è di valore nullo all’esterno di essa, il che comporta che l’energia del burst non è completamente concentrata come nel caso di un tono puro bensì interessa una banda molto vasta. L’inganno funziona molto bene in termini di evidenziazione delle non linearità elementari (componenti armoniche e di intermodulazione), ma anche di altri fenomeni, di natura lineare e non lineare, dei quali ci interesseremo nel prossimo futuro.
Ci si potrebbe pertanto ragionevolmente chiedere se queste due considerazioni non inficino la validità dei risultati ottenuti ed abbiamo già affermato che così non è, ma certo non ci siamo solo basati sulla (pur ampia) casistica finora raccolta, in quanto:
- Negli altoparlanti molte delle non linearità di trasferimento sono largamente legate all’escursione, e quindi l’effetto di offset iniziale potrebbe effettivamente portare il sistema a lavorare in condizioni di minore linearità. Tuttavia l’extra spostamento transitorio perdura solo per un numero molto limitato di cicli di segnale e per minimizzarne le conseguenze basta non pretendere di usare la finestra anecoica fino ai limiti teorici di estensione verso il basso. Nel nostro caso, e nelle attuali condizioni di misura, il limite inferiore di anecoicità vale circa 90 Hz, ma la prima frequenza analizzata non in campo vicino vale 375 Hz, corrispondenti a 4 cicli di segnale. Il necessario ricorso ad una finestra di pesatura limita poi ulteriormente e drasticamente le conseguenze degli eventuali offset.
- Anche se non tutta l’energia del segnale applicato è collocata nel piccolo intorno della frequenza nominale di prova, il solo aspetto fondamentale è che l’altoparlante raggiunga una escursione molto prossima a quella cui verrebbe obbligato da un segnale stazionario, il che è pure verificato nelle condizioni espresse al punto precedente.
Il setup di misura
L’implementazione concreta della tecnica suddetta è stata effettuata su un sistema Audio Precision System One, redigendo programmi esecutivi in ambiente APWin. Dato il rate di acquisizione (48 kHz) ed i limiti di anecoicità prima indicati, sono state sintetizzate le frequenze di misura con l’ovvia accortezza di farle coincidere con la frequenza nominale di uno dei canali di analisi disponibili. Una volta impostato il livello desiderato, la misura viene effettuata in modo automatico ed in due fasi: in campo vicino fino a 400 Hz, con un set microfonico che può arrivare a tre unità in modo da prelevare con il peso opportuno eventuali sezioni accordate, poi ad un metro di distanza. Nella prima la durata dei burst vale 350 millisecondi, nella seconda si scende a 12 ms. In ambo i casi il ciclo di ripetizione vale 2.5 secondi, per cui in gamma medio-alta la potenza media dissipata vale meno di 1 watt anche chiedendo di effettuare il test a 200 watt. Riguardo gli aspetti più propriamente esecutivi dei test c’è da annotare che tutti i dati raccolti in campo libero vengono elaborati mediante post-processamento, perché un aspetto critico del processo risiede nella anecoicità del treno d’onde analizzato e ciò comporta l’impossibilità di fissare un solo istante di partenza del trigger (per via della differente posizione relativa delle vie rispetto al microfono di misura). I burst vengono cioè acquisiti, precontrollati per evitare acquisizioni casualmente errate, memorizzati, analizzati per stabilire il punto di partenza della sequenza valida e poi trasformati.
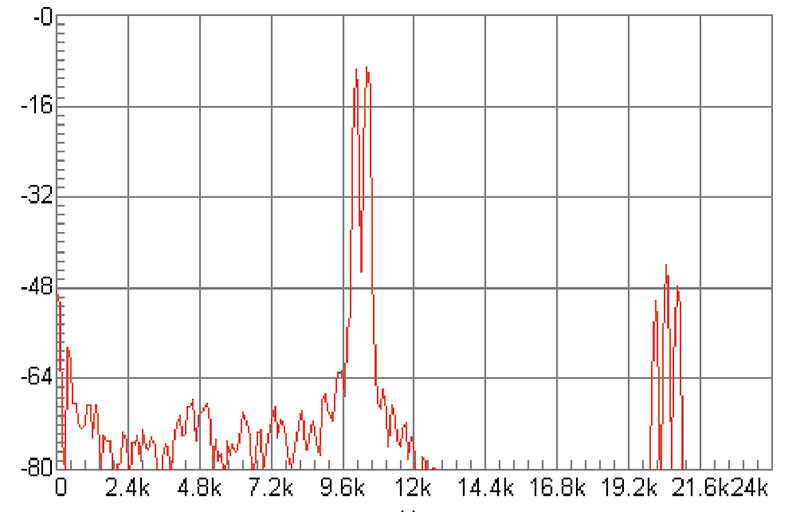
Figura 5. Gli altoparlanti sono componenti del tutto peculiari in termini di struttura della distorsione prodotta. Nel caso riportato, tutt’altro che infrequente, il tweeter sotto test ha “inventato” una componente armonica intermedia e prevalente rispetto alle seconde armoniche del segnale bitonale applicato, relativa ad una fondamentale che non esiste.
Livelli di prova e rappresentazione dei risultati
Fino ad oggi abbiamo eseguito le misure di distorsione armonica per un livello medio di 90 dB. Da oggi, su Digital Video, le eseguiremo a 100 dB, ovvero ad una potenza 10 volte superiore, perché in un sistema audio-video le performance ottenibili a livelli di ascolto sostenuti hanno un peso maggiore rispetto all’ascolto della sola musica. Ad un diffusore da 86 dB di sensibilità, per esempio, verranno applicati treni d’onde da 25 watt a tutte le frequenze in cui sia possibile non superare i limiti meccanici di escursione (il che equivale a dire che se stiamo provando un piccolo canale centrale faremo partire la misura probabilmente da 80 Hz, non da 20). In casi particolari (sistemi grandi e “robusti”) saliremo ancora, ma rimanendo sempre nell’ambito delle pressioni ragionevolmente richiedibili nell’uso concreto. Riguardo i dati rappresentati e le modalità di rappresentazione, i cambiamenti sono importanti. Fino ad oggi abbiamo infatti riportato la distorsione armonica, intesa come prodotti di II e III ordine, insieme alla risposta in frequenza, sollevando le curve di 30 dB in un grafico rappresentante una dinamica complessiva di 50 dB. Le curve di distorsione erano inoltre di tipo “assoluto”, ovvero indicavano un livello di pressione e quindi, per trovare il valore della distorsione in un punto, occorreva determinare la distanza in dB della curva di distorsione da quella della risposta e diminuire il valore ottenuto di 30 dB. Il grafico attuale è invece di tipo “relativo”, ovvero va letto direttamente in termini di distorsione (che è data da un rapporto di valori) e si estende su una scala ampia 80 dB, da +10 (distorsione 316%) a -70 (0.0316%). Le curve riportate sono 4, e cioè:
- Linearità dinamica (curva nera), intesa come differenza tra il livello misurato sulla fondamentale e livello atteso sulla base della misura della pressione in regime stazionario ad un watt.
- Seconda armonica (curva blu).
- Terza armonica (curva rossa).
- Quarta armonica (curva verde).
- Quinta armonica (curva azzurra).
La linearità dinamica è una novità completa e non va assolutamente scambiata con una curva di risposta: è bensì un indice di coerenza della risposta al variare del livello, e nel caso ideale si presenta quindi come un segmento di retta assestato sullo 0 dB. Nessun sistema di altoparlanti è però in grado di garantire un risultato siffatto a pressioni elevate a bassa frequenza, ed a 100 dB c’è quindi da attendersi una certa flessione verso le frequenze inferiori. Anche gli ordini IV e V non sono mai stati riportati in precedenza, e se abbiamo deciso di farlo è perché abbiamo osservato che in taluni casi raggiungono livelli consistenti (in particolare la quinta, laddove sussista una forte simmetria comportamentale dei trasduttori) e possono pertanto incidere anche pesantemente sulla qualità percepita, tenendo presente che in generale l’udibilità di una componente aumenta con la sua distanza dalla fondamentale; il programma comunque misura fino alla settima armonica, e semmai sarà utile pubblicheremo anche i valori degli ordini superiori.
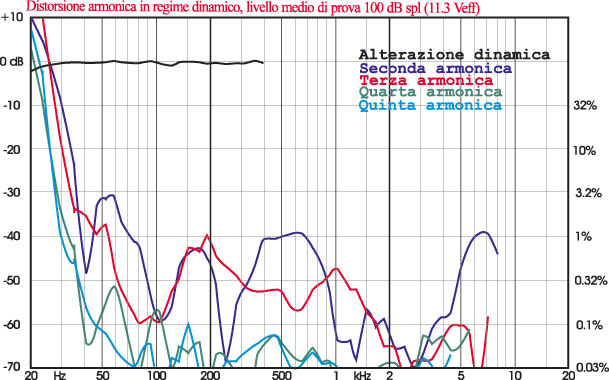
Figura 6. Esempio di andamento della distorsione a 100 dB di un ottimo sistema di altoparlanti. Notare come a bassissima frequenza tutti gli ordini di distorsione eccedano il livello della fondamentale, generando cioè distorsioni superiori al 100%.
Conclusioni
Abbiamo introdotto e discusso una metodica di misura semplice e potente per quantificare le distorsioni dei sistemi di altoparlanti, a livelli e con segnali congruenti con quelli di cui si compone la musica e l’audio dei film. I risultati a bassa potenza sono in armonia con quelli ottenuti con le procedure classiche basate su segnali stazionari o lentamente variabili, quelli a potenza elevata appaiono di grande interesse in termini di discriminazione tra i prodotti in commercio. Chiunque, a questo punto, si porrà una domanda come la seguente “va bene, sembra una misura interessante: ma l’orecchio cosa ne pensa?…”
A questo proposito abbiamo detto altre volte che in tema di misure video, a dispetto della “giovinezza” dei test, c’è già un accordo eccellente tra “visualisti” e “misuristi”, categorie che in effetti non esistono (Manuti, Frattaroli ed il sottoscritto, ad esempio, “militano” in entrambe) ma che vogliamo comunque ipotizzare per poterle portare ad esempio ad altre, che invece esistono o si vorrebbero entrambe esistenti per davvero nel mondo dell’audio ad alta fedeltà: i famigerati “misuroni” ed “ascoltoni”. Dai primi risultati comparativi grafici/ascolto sembra proprio che le misure di distorsione in regime dinamico siano riuscite, se non già ad aprire una breccia, quantomeno a scalzare qualcuno dei mattoni del muro eretto vent’anni or sono da entrambe le fazioni. Noi, come sempre, continuiamo a lavorare con umiltà per farlo franare del tutto…
di Fabrizio Montanucci
da Digital Video n. 20 gennaio 2001

